合并
一旦所有流的数据可用,就使用合并节点来组合来自多个流的数据。
1.49.0 中的细微变化
n8n 1.49.0 版本引入了添加两个以上输入的选项。旧版本最多仅支持两个输入。如果您正在运行旧版本,并且想要在这些版本中合并多个输入,请使用
代码节点。模式
> SQL 查询功能也是在 n8n 版本 1.49.0 中添加的,但在旧版本中不可用。节点参数
您可以通过选择
模式来指定合并节点如何组合来自不同数据流的数据:附加
保留所有输入的数据。选择
输入数量,逐个输出每个输入项。节点等待所有连接的输入执行完毕。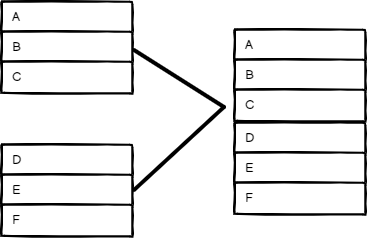
结合
合并两个输入的数据。在
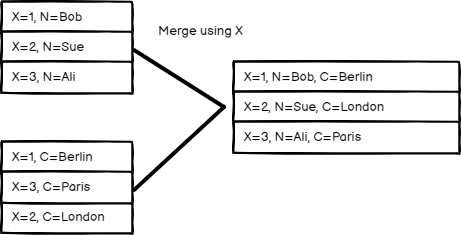
“合并方式”中选择一个选项,以确定合并输入数据的方式。匹配字段
按字段值比较项目。在
“要匹配的字段”中输入要比较的字段。n8n 的默认行为是保留匹配项。您可以使用
“输出类型”设置更改此设置:- 保留匹配项:合并匹配的项。这类似于内连接。
- 保留不匹配项:合并不匹配的项目。
- 保留所有内容:将匹配的项合并在一起,并包含不匹配的项。这类似于外连接。
- 丰富输入 1 :保留输入 1 中的所有数据,并添加输入 2 中的匹配数据。这类似于左连接。
- 丰富输入 2 :保留输入 2 中的所有数据,并添加输入 1 中的匹配数据。这就像右连接。
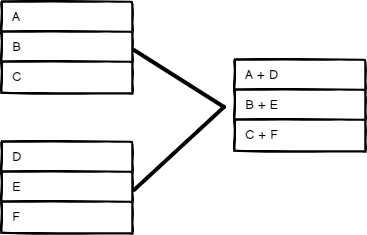
位置
根据项目的顺序进行合并。输入 1 中索引 0 处的项目将与输入 2 中索引 0 处的项目合并,依此类推。
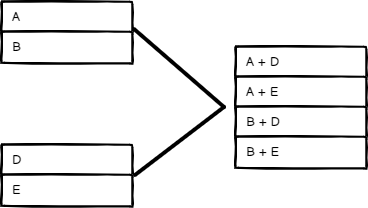
所有可能的组合
输出所有可能的项目组合,同时合并同名的字段。
组合模式选项
当通过
模式 > 合并 合并数据时,您可以设置以下选项:- 冲突处理:选择当数据流发生冲突或存在子字段时如何合并。有关详情,请参阅冲突处理。
- 模糊比较:比较字段时是否容忍类型差异(启用)或不容忍(禁用,默认)。例如,启用此功能时,n8n 会将和视为相同。
- 禁用点符号:这可以防止使用字段名称访问子字段。
- 多重匹配:选择 n8n 在比较数据流时如何处理多重匹配。
- 包含所有匹配
- :如果有多个匹配,则输出多个项目,每个匹配对应一个。
- 仅包含第一个匹配
- :保留每个匹配的第一个项目,并丢弃其余的多个匹配。
- 包含任何未配对的项目:选择按位置合并时保留还是丢弃未配对的项目。默认行为是忽略不匹配的项目。
冲突处理
如果索引中的多个项目具有相同名称的字段,则会发生冲突。例如,如果输入 1 和输入 2 中的所有项目都包含一个名为 的字段,则这些字段会发生冲突。默认情况下,n8n 会优先处理输入 2,这意味着如果输入 2 中有值,n8n 会在合并项目时使用该值。
您可以通过选择
“选项” > “冲突处理”来更改此行为:- 当字段值发生冲突时:选择要优先考虑的输入,或选择始终将输入编号添加到字段名称以保留所有字段和值,并将输入编号附加到字段名称以显示其来自哪个输入。
- 合并嵌套字段
- 深层合并
- :合并项所有层级的属性,包括嵌套对象。这在处理复杂的嵌套数据结构时非常有用,因为您需要确保所有层级的嵌套属性都已合并。
- 浅层合并
- :仅合并项顶层的属性,而不合并嵌套对象。当您拥有扁平的数据结构,或者您只需要合并顶层属性而不必担心嵌套属性时,这非常有用。
SQL查询
编写自定义 SQL 查询来合并数据。
例子:
1 | |
先前节点的数据以表的形式提供,您可以根据它们的顺序在 SQL 查询中将它们用作输入 1、输入 2、输入 3 等。请参阅
AlaSQL GitHub 页面,查看受支持 SQL 语句的完整列表。选择分行
选择要保留的输入。此选项始终等待两个输入的数据可用。您可以选择
输出:- 输入1 数据
- 输入2 数据
- 单个空项目
节点输出所选输入的数据,但不对其进行更改。
模板和示例
没有任何
合并项目数量不均匀的数据流
传入合并节点输入 1 的项目将优先处理。例如,如果合并节点在输入 1 中收到 5 个项目,在输入 2 中收到 10 个项目,则它只会处理其中 5 个项目。输入 2 中剩余的 5 个项目不会被处理。
使用 If 和 Merge 节点执行分支
0.236.0 及以下版本
n8n 在 1.0 版本中移除了此执行行为。本节适用于使用
v0(旧版)工作流执行顺序的工作流。默认情况下,这适用于所有在 1.0 版本之前构建的工作流。您可以在工作流设置中更改执行顺序。如果将合并节点添加到包含 If 节点的工作流中,则会导致 If 节点的两个输出数据流都执行。
一个数据流触发合并节点,然后合并节点执行另一个数据流。
例如,下图中有一个工作流,包含“编辑字段”节点、“如果”节点和“合并”节点。“如果”节点的标准行为是执行一个数据流(在下图中,这是
真正的输出)。然而,由于“合并”节点的存在,尽管“如果”节点没有向“错误”数据流发送任何数据,但两个数据流都会执行。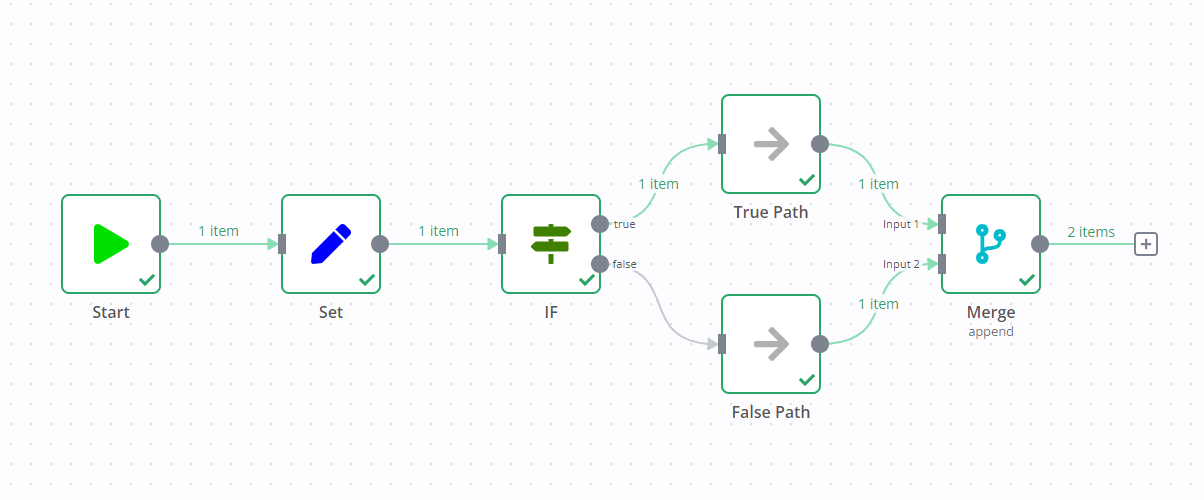
尝试一下:一步一步的示例
创建一个包含一些示例输入数据的工作流来尝试合并节点。
使用代码节点设置示例数据
- 在画布上添加一个 Code 节点并将其连接到 Start 节点。
- 将以下 JavaScript 代码片段粘贴到JavaScript 代码字段中:
- 添加第二个 Code 节点,并将其连接到 Start 节点。
- 将以下 JavaScript 代码片段粘贴到JavaScript 代码字段中:
尝试不同的合并模式
添加合并节点。将第一个代码节点连接到
输入 1 ,将第二个代码节点连接到输入 2 。运行工作流将数据加载到合并节点。最终的工作流程应如下所示:
没有任何
现在尝试
模式中的不同选项,看看它如何影响输出数据。附加
选择
模式>附加,然后选择执行步骤。表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候 |
|---|---|---|
| 斯蒂芬 | 德 | |
| 吉姆 | 英文 | |
| 汉斯 | 德 | |
| 英文 | 你好 | |
| 德 | 你好 |
按匹配字段合并
您可以合并这两个数据输入,以便每个人都能获得适合其语言的正确问候语。
- 选择模式>合并。
- 选择“按以下方式合并” > “匹配字段” 。
- 在输入 1 字段和输入 2 字段中,输入。这告诉 n8n 通过匹配每个数据集中字段中的值来组合数据。
- 选择执行步骤。
表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候 |
|---|---|---|
| 斯蒂芬 | 德 | 你好 |
| 吉姆 | 英文 | 你好 |
| 汉斯 | 德 | 你好 |
按位置合并
选择
模式>组合、按组合>位置,然后选择执行步骤。表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候 |
|---|---|---|
| 斯蒂芬 | 英文 | 你好 |
| 吉姆 | 德 | 你好 |
保留未配对的物品
如果要保留所有项目,请选择
添加选项>包含任何未配对的项目,然后打开包含任何未配对的项目。表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候 |
|---|---|---|
| 斯蒂芬 | 英文 | 你好 |
| 吉姆 | 德 | 你好 |
| 汉斯 | 德 |
按所有可能的组合进行组合
选择
模式>组合、组合方式>所有可能的组合,然后选择执行步骤。表格视图中的输出应如下所示:
| 姓名 | 语言 | 问候 |
|---|---|---|
| 斯蒂芬 | 英文 | 你好 |
| 斯蒂芬 | 德 | 你好 |
| 吉姆 | 英文 | 你好 |
| 吉姆 | 德 | 你好 |
| 汉斯 | 英文 | 你好 |
| 汉斯 | 德 | 你好 |